近日,云从科技和上海交通大学在自然语言处理领域取得重大突破,在卡内基-梅隆大学发起的大型深层阅读理解任务数据集RACE数据集上登顶第一,并成为世界首个超过人类排名的模型。
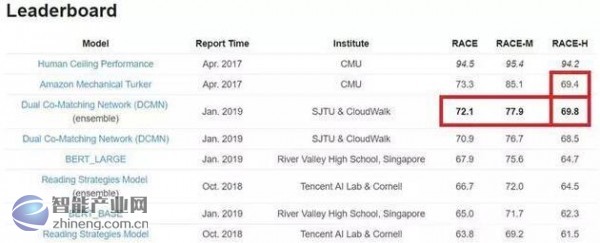
云从科技与上海交通大学首创了一种阅读信息匹配机制——DCMN模型,使机器的正确率达到72.1%,较之前最好结果(67.9%)提高了4.2个百分点,并在高中测试题部分首次超越人类69.4%的成绩。
有种题型叫“阅读理解”
不管是中文、英语还是任意其他语言,阅读理解都算得上是最难的题型之一,需要信息收集、知识储备、逻辑推理、甚至还要融会贯通的主观作答。
微软创始人比尔·盖茨曾经表示,“语言理解是人工智能领域皇冠上的明珠”。
机器阅读理解,是指机器通过阅读和理解大量文字,有效整理和总结出人类所需要的信息。
按照人工智能技术发展路径,在机器视觉、语音识别等智能感知技术在性能上趋于饱和之后,下一个人工智能的突破就是自然语言处理等认知决策技术。技术上形成从智能感知到认知决策的闭环,在机器上体现为会理解、会思考、会分析决策,人机交互方式更加便捷,将对各行各业将产生颠覆式创新。
例如为证券投资提供各种分析数据,进行金融风险分析、欺诈识别;在社交软件、搜索引擎辅助文字审阅和信息查找;还可以帮助医生检索和分析医学资料、辅助诊断等等。
RACE数据集
RACE数据集(ReAding Comprehension dataset collected from English Examinations)是一个来源于中学考试题目的大规模阅读理解数据集,包含了大约28000个文章以及近100000个问题。
它的形式类似于英语考试中的阅读理解(选择题),给定一篇文章,通过阅读并理解文章(Passage),针对提出的问题(Question)从选项中选择正确的答案(Answers)。
RACE数据集的难点在于,该题型的正确答案并不一定直接体现在文章中,只能从语义层面深入理解文章,通过分析文中线索并基于上下文推理,选出正确答案。
相对以往的抽取类阅读理解,算法要求更高,被认为是“深度阅读理解”。
DCMN模型
针对这种“深度阅读理解”,云从科技与上海交通大学首创了一种P、Q、与A之间的匹配机制,称为Dual Co-Matching Network(简称DCMN),并基于这种机制探索性的研究了P、Q、与A的各种组合下的匹配策略。
01 DCMN匹配机制
以P与Q之间的匹配为例:
云从科技和上海交大使用目前NLP最新的研究成果BERT分别为P和Q中的每一个Token进行编码。基于BERT的编码,可以得到的编码是一个包含了P和Q中各自上下文信息的编码,而不是一个固定的静态编码,如上图中Hp与Hq;
其次,通过Attention的方式,实现P和Q的匹配。具体来讲,是构建P中的每一个Token在Q中的Attendances,即Question-Aware的Passage,如上图中Mp。这样得到的每一个P的Token编码,包含了与Question的匹配信息;
为了充分利用BERT带来的上下文信息,以及P与Q匹配后的信息,将P中每个Token的BERT编码Hp,与P中每个Token与Q匹配后的编码Mp进行融合, 对Hp和Mp进行了元素减法及乘法操作,通过一个激活函数,得到了P与Q的最终融合表示,图中表示为Spq;
最后通过maxpooling操作得到Cpq,l维向量,用于最后的loss计算。
02 各种匹配策略研究
除了P与Q之间的匹配之外,还可以有Q与A、P与A之间的匹配,以及不同匹配得到的匹配向量间的组合,这些不同的匹配与组合构成了不同的匹配策略。对七种不同的匹配策略分别进行了试验,以找到更加合适的匹配策略,分别是:
[P_Q; P_A; Q_A], [P_Q; P_A], [P_Q; Q_A], [P_A; Q_A], [PQ_A], [P_QA], [PA_Q]
“PA”表示先将P和A连接为一个序列,再参与匹配,“PQ”与“QA”同理。符号“[ ; ]”表示将多种匹配的结果组合在一起。
7种不同策略经试验后,得出采用PQ_A的匹配策略,即先将P与Q连接,然后与A匹配,无论是在初中题目(RACE-M)、高中题目(RACE-H)还是整体(RACE),都得到了更优的结果。
虽然目前机器在一些阅读理解数据集上的水平已经超过了人类,但这并不能表明“机器打败了人类”,对于自然语言处理、对于人工智能,我们仍有一大步需要前进。
- 东方通与天津联通签约天津市云计算产业生态合作协议
- 中国移动携手启明星辰发布数字政府网络安全系列指引 助力打造数字政府
- 北信源宣布通过百度智能云接入文心一言能力 打造人工智能全系产品服务
- 两会看点|国产基础软件扬帆启新程 麒麟软件奋楫当自强
- 新炬网络宣布接入百度“文心一言” 提升智能运维与数字员工智能产品
- 聚势而强 合力共赢 麒麟软件携手海光信息共助天津信息产业发展
- 东方通入选中国信通院《高质量数字化转型产品及服务全景图》
- 润和软件与华为政务一网通军团签约 携手深耕城市数字化
- 聚焦科技自立自强 Bonree ONE 助力国产办公自动化平稳替代
- 博睿数据入选中国信通院《高质量数字化转型产品及服务全景图》